Curvenote Blog

Curvenote launches Notebooks Now! at the American Geophysical Union Annual Meeting in San Francisco, where 20,000+ scientists descended on Moscone Center for five days of wide open science.

Curvenote and ExecutableBooks were at JuptyerCon 2023 in Paris, between all the amazing announcements & talks, here are our main takeaways.

Mike Morrison, the designer of the #betterposter movement, is joining Curvenote on a mission to improve scientific articles.

Curvenote and MyST websites create structured data, which can be rendered by any number of "theme servers", which are in charge of turning that structured data into a reading experience.

Webinar - Learn how to write your next paper, report or even your thesis in MyST Markdown to create PDFs and interactive web articles.
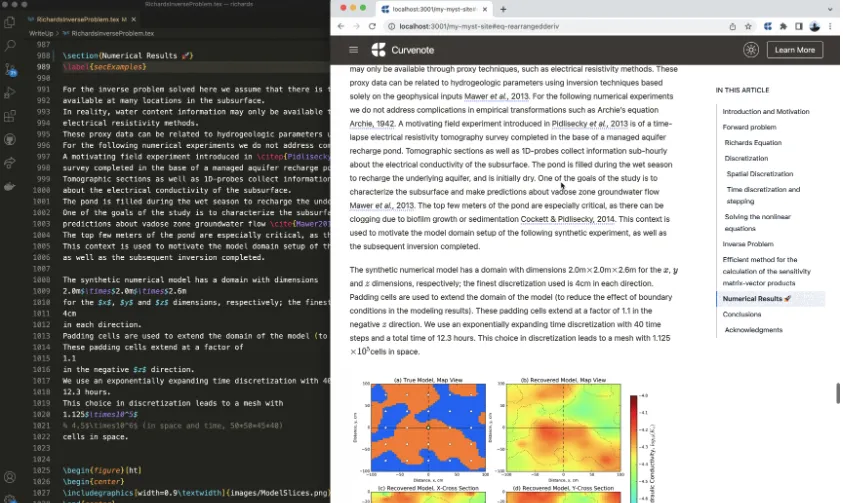
The MyST command-line tools can now parse and render LaTeX documents, we explore some of the process behind creating this feature.

Create BibTex files for your Curvenote project using Paperpile. This guide shows two ways to easily connect Paperpile to Curvenote to make reference management easy.

A Curvenote webinar taking attendees through publishing and updating research websites directly from the Curvenote visual editor

We are presenting a walkthrough of Curvenote’s publishing capabilities at RSECon 2022, in Newcastle.

Easily share scientific content and Jupyter Notebooks online, all you need to start is GitHub or GitLab repository and you can be up and running in 60 seconds.

This week we hosted a webinar showing off our new publishing in-app no-code publishing features

You can now interface with Curvenote through the command line using our new CLI. Eaily export your content, work locally with MyST Markdown, or export to any PDF, Word or LaTeX template.

Export your Curvenote articles to MyST Markdown to locally edit the content. MyST Markdown is a new specification of Markdown that allows you to write professional documents, books and websites.

Using the Curvenote CLI to create an open research website with a local Markdown based authoring experience.

An orcid.org is a persistent digital identifier for researchers which is widely used. You can now conenct your ORCID account directly to your Curvenote profile.

Enhancing FAIR Data Workflows through use of PIDs in Curvenote and beyond.

Publishing Curvenote sites became even easier last week when we launched our new publish button in the Curvenote editor.

You can now publish directly from the Curvenote platform, including setting domains in the project settings.

A presentation on the challenges with today’s tools for research communication & collaboration, and present a vision for the future.

Lightning talks at the Transform22 event, (1) deploying a scientific website in 4.5 minutes; and (2) things learned at FORCE11.

We added thumbnails to the article frontmatter, as well as met up with the whole Curvenote team in person for the first time!

We overhauled the curvenote.com site to make better use of the new publishing tools and CLI.

In this tutorial we go over how to turn your Jupyter Notebooks into a scientific paper.

We integrated the open-source thebe-core with the JupyterLite project allowing Python based notebooks to be executed in-browser.

We released try.curvenote.com to make it easier to create a Curvenote site!

Our goal with Curvenote is to introduce tools that can lower the barrier to linking, tracking, and enable the possibility to collaboratively act on improvements.

One of the biggest frustrations in using what you see is what you get (WYSIWYG) editors when coming from knowing Markdown is how they deal with inline code.

How does open-science allow us to reimagine how we stand on the shoulders of giants?

Version control in Curvenote works across a scientists' content, code and results making it easy to track, reuse and collaborate around their work

We released the first version of our command-line tools and are prepping for a webinar next week!

We added all sorts of scholarly metadata, including licenses, DOIs, arXiv links, open access statements, binder & GitHub links, and more.

Reflections on distinct modes of collaboration in science including gathering feedback, asynchronous co-authoring and review, and real-time simultaneous editing.

This week we investigated Jupyterlite, and worked hared on getting the work out about Curvenote on twitter and medium!
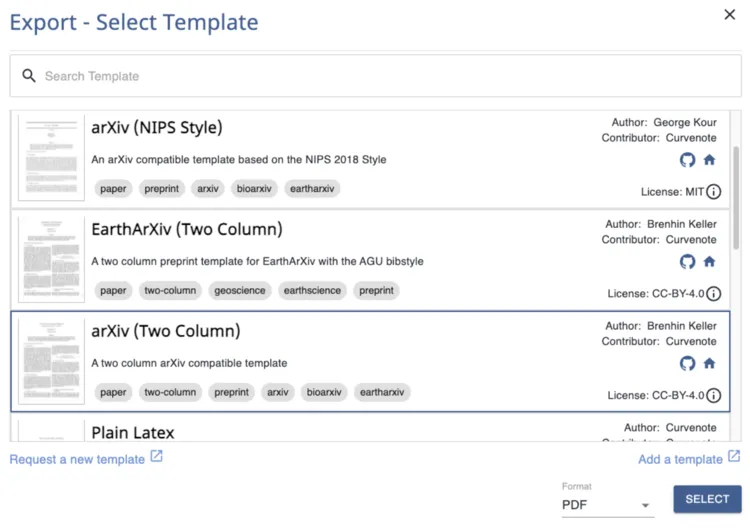
Writing up research for submission to a particular conference, journal, or preprint service is a major task. Exporting to a PDF should be easy!

We show off an example of an archeology article, a sneak peek and the new website, and discuss creating LaTeX diffs for pdfs.

Introducing a lightweight templating engine, jtex, that provides a simple command line interface (CLI).

We introduced the Volcanica journal in response to a user request.

Exporting to Microsoft Word is now a single click in Curvenote!

The Curvenote brand embodies aspects of reuse, modularity and the connections behind ideas through building blocks that provide structure and can also be pulled apart, rearranged and used in unique ways.

Introducing Curvenote Pro, which includes additional private projects, advanced publishing, and export to any professional template.

This week we added export templates for arXiv, EarthArXiv and Volcanica, we also are working towards a rebrand of Curvenote.

This week we released an update of our Navigation panel we also showcase some of the public projects that are being developed on Curvenote.

This week we released new hover popovers for links as well as improved the SEO for users articles.

This week we released export templates and dive into details of the templating mini-language, jtex, that we're defining.

This week we introduced changes for internal cross-referencing of content and citation management improvements.

The initial page load of Curvenote is now 50% faster ⚡⚡⚡

This week we released improvements to our metadata and tagging to show thumbnails when you share an article. We also went through some of the recent changes and fixes in the Curvenote app and extension.

This week we're talking about version control via Curvenote - the current workflows and thoughts on future changes.

We are working on exporting Curvenote articles as LaTeX and PDF, as well as improving image and figure captioning and referencing.

Curvenote was chosen to participate in a science & technology innovation program called Creative Destruction Lab.

Curvenote was selected as one of 8 Canadian companies with over 16,000 global applications to participate in YCombinator W21, which is the premier startup accelerator in Silicon Valley.

Curvenote is a Gold Sponsor of the upcoming the FORCE11 2021 conference.

Our notes from the FORCE11’s 2021 Annual Conference with over 1,300 participants.

A webinar using Curvenote for scientific writing and integration with Jupyter notebooks.

An interview with Dr. Lindsey Heagy, an assistant professor in Earth Data Science and researcher at the University of British Columbia. Lindsey is also a Science Advisor for Curvenote.

Using Curvenote’s Jupyter extension and editing tools to keep track of research notes and progress.
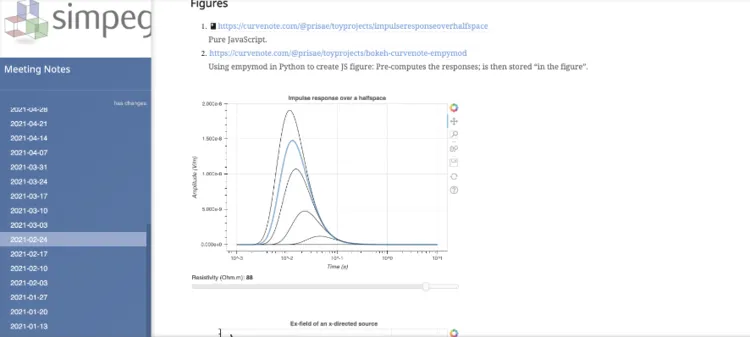
Learn how the SimPEG team uses Curvenote for their weekly meetings, embedding interactive figures and references to notebook code and outputs.

Improve reproducible research by linking together your articles and your Jupyter Notebooks. You can make it easy for others to view, edit, and use your data and research - whether that’s across disciplines, industries or just within your own department.

How to integrate open source and reproducibility practices into presenting educational materials.

Open science is fundamentally changing how scientists and researchers approach scholarly communication and collaboration, from publishing preprints and interactive research results.

Research techniques have evolved, but our tools for communicating and collaborating have not. Curvenote aims to unify scientific research, education, & publishing, by providing a platform where scientific ideas can be developed and published in an interactive and accessible way.

At JupyterCon 2020 we introduce Curvenote, allowing you to sync content between Jupyter Notebooks and a web-based, collaborative document editor.

Lightning talk at Transform 2020, on how we reuse ideas and move them forward together.